Our June 6th meeting brought Mark Weiss and Andy Woodruff to explain the technology underlying still and video cameras. Mark has extensive experience in videography and audio recording. He has spoken before to DACS on the transition to HDTV back in August 2008. Andy is a DACS member who was the videographer for some of John Patrick’s presentations and led the Video Production workshop last year.
The presentation was a deep dive into some of the technologies involved, and it was apparent that this is a vast subject. Mark and Andy traded off frequently as they covered the topics. Broadly they covered camera types, optics, and went into much detail on the subject of color. They also displayed some professional level camera equipment.
Cameras can be categorized as consumer models, prosumer models, and professional models.
Consumer models include point-and-shoot still cameras, consumer video cameras, and cellphone cameras.
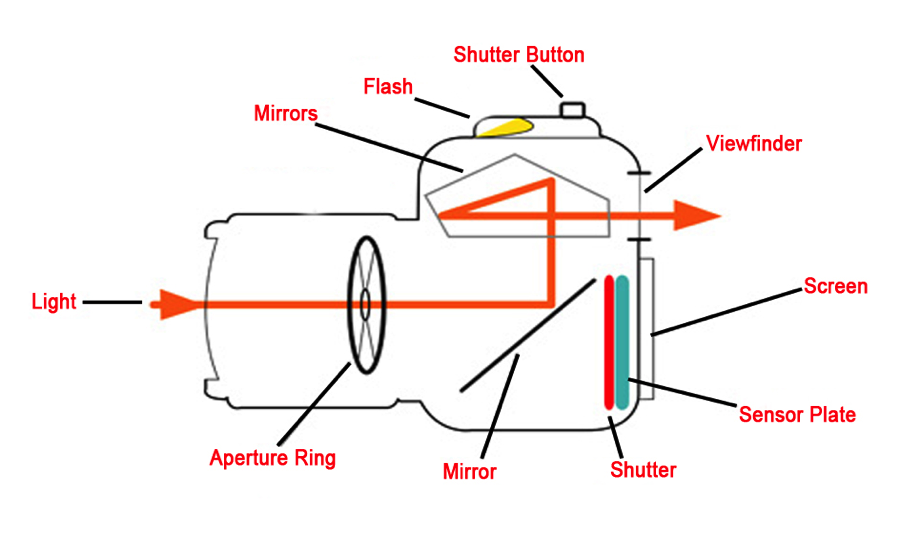
DSLR Camera Diagram
Prosumer models include digital single lens reflex cameras. Digital single lens reflex (DSLR) cameras are the digital versions of SLR cameras that predate the digital age. SLR and DSLR cameras provide the benefit that the viewfinder displays an image from the main lens; simpler and earlier cameras included a separate smaller lens for the viewfinder. The SLR and DSLR therefore show exactly the view that will be recorded on film or digitally, even as the user changes lenses or adjusts a zoom lens. One of the presentation slides illustrated how the mirror in an SLR or DSLR swings out of the way, so that light from the image reaches the sensor. The category of prosumer models also includes mirrorless cameras and camcorders. Mirrorless cameras provide many of the advantages of SLR and DSLR cameras, but the mirrorless cameras reduce the moving parts and can be made smaller and lighter. Camcorders are video recorders above the consumer level.
Finally, the professional category ($3,000 to $100,000) includes more sophisticated DSLRs, cinematic cameras, and broadcast cameras. These cameras have better resolution and color recording, and they can work at lower lighting levels than prosumer models.
The image quality of any digital camera is based on the image sensor inside the camera. Mark and Andy pointed out that an important gauge is the size of the sensor. Larger sensors generally provide better resolution. However, larger sensors also imply that all dimensions of the lens and other optical parts are larger. The smaller and larger sensors may have the same stated resolution, i.e. the number of pixels may be the same. However, the individual pixels are proportionately larger in the larger sensors. The larger pixels lead to less “noise” and better lower level light response. The size of a sensor can be described by its rectangular dimensions in millimeters, but photographers more typically refer to the crop factor. This is a relative gauge of the sensor size, as compared to the sensor size of a 35mm camera (that was typical for decades in the film world). A digital camera that has a sensor of the same dimensions as an image on 35mm film is said to have a crop factor of 1.0. A sensor that is half that size (half the dimension in each direction of the rectangular sensor) has a crop factor of 2.0. Professional digital cameras (whether still or video) typically have a crop factor of 1.0 to 1.5. Prosumer cameras are typically around 1.6 to 2.0. Cellphone and other consumer cameras are typically around 6.0.
Mark and Andy described the familiar parameters of focal length, aperture, shutter speed, and ISO. They showed pictures of two lenses, one with a short focal length that showed a wide-angle view and one with a long focal length that showed a more magnified view. The aperture determines how much light passes through the optics, and this is measured by the “f-number” or “f-stop”. A lower f-number lets in more light. Shutter speed is the time that the shutter is open; this exposure duration is typically measured as a fraction of a second. ISO is the film speed or sensitivity of the film or sensor. A higher number is used in low light situations.
Photographers use the term “stop” in conjunction with shutter speed, aperture, and ISO number. If you change the shutter speed from 1/100 sec to 1/50 sec, you could say that you are lengthening the shutter speed by one stop. One stop means a doubling of the amount of light. The aperture requires special treatment, because a doubling of each dimension implies a quadrupling of the total area. Therefore, if you change the aperture from f/8 to f/4, you have increased the aperture by two stops. Meanwhile, if you change the ISO from ISO 800 to ISO 1600, you have increased the ISO by one stop.
The depth of field is a measure of the range of distances at which objects are in focus, and this is determined by a combination of focal length, f-number, and the distance between the camera lens and the object.
There are tradeoffs between aperture, shutter speed, ISO, and depth of field. Typically, you would like to use:
- a low ISO for low noise and therefore a less grainy photograph
- a fast shutter speed to prevent blur
- a smaller aperture (higher f-number) for a larger depth of field
In some situations you may be able to use all three of these (typically outdoors with a lot of light). However, more often you need to take a compromise among these three. Consumer models rely on an automatic mode of the camera to try to balance these factors. On better cameras, you can adjust settings to favor these factors as you like. For instance, perhaps you are capturing sports activity and want to show some motion blur rather than freeze the motion. You can set the camera for a shutter speed that will provide the desired amount of motion blur. Or perhaps you are using a tripod to photograph a nature scene at dusk. In this case, you might want to use a low ISO and a very long exposure to let in sufficient light; the automatic mode of a consumer camera would not provide this option.
Next, the speakers got to the phenomenon of the diffraction resolution limit that is due to the wave nature of light and how these waves diffract around the edges of a small hole. This means that, surprisingly, you may get more rather than less blur with a high f-number. They talked about the “circle of confusion” which occurs when the image focus is not exactly on the film plane, but behind or in front of it. They also discussed optical distortion; lens designers try to avoid distortion and uneven lighting at the edges and corners of an image.
The next topic was dynamic range, i.e. the range of lightness levels from black to white. Mark and Andy explained that human eyes have an essentially logarithmic response to light level. This means that, if a doubling of the actual light produces a certain increase in the apparent light level to our eyes, then another doubling of the actual light is necessary to obtain another similar apparent increase.
Camera sensors, on the other hand, have a linear response to light level. This means that human eyes and camera sensors respond very differently to light brightness. Specifically, it also means that human eyes are better than uncompensated camera sensors at seeing gradations of darkness in dark shadow areas.
In still cameras, there is a method to overcome the loss of image quality due to the logarithmic versus linear responses of eye and camera sensors. Prosumer and professional still cameras can save images in RAW format, which is an essentially unprocessed format based more directly on camera sensor data. The more typical image output format is the JPEG file that is also commonly used in internet sites. The JPEG format is compressed and “lossy”, but it saves space. RAW formats are proprietary and vary from manufacturer to manufacturer, and they involve much larger files that cannot be displayed by most browsers or image viewers. You must use a program such as Adobe Photoshop to edit a RAW file, and this program provides various adjustments to compensate for the logarithmic versus linear conundrum.
In video cameras, there is also a method to overcome this issue. Professional video cameras and some prosumer video cameras include firmware so that the camera can essentially convert the sensor linear data to logarithmic data. The method is known as shooting “log video”, and it provides more ability to record gradations within shadows. The details are proprietary to each manufacturer; Sony’s system is called S-Log, and Canon’s is called C-Log. You also need an appropriate program when you edit the files, similar to the still camera RAW file editing requirements. In the case of video, the log video formats must be processed with a program like Adobe Premiere that can utilize Look Up Tables (LUTs). Look Up Tables are used to translate from the gamma compression in the camera to the monitor display space.
When you hear the term 4K in the consumer world, this typically refers to a 16 by 9 aspect ratio of 3840 by 2160 pixels as found on many newer televisions. However, Mark and Andy said that the term actually referred in past years to a larger 17 by 9 format. The 4K term has been recently misappropriated by television marketing departments. Those televisions should more correctly be described as UHD. Now that the meaning of 4K has been changed by this marketing effort, engineers are referring to the larger 17 by 9 format as “True 4K”, in order to distinguish it. Cinematic films have this 17 by 9 aspect ratio, which corresponds to 4096 by 2160 pixels. Mark and Andy said that they both have True 4K monitors, so that they can edit real cinematic films. Meanwhile, these films will not fit correctly on a Samsung “4K” monitor, because those monitors are not quite wide enough.
Mark and Andy described the physics of sensors. Mark described a pixel as like a container that can fill up with charge from photons and can reach a point where it registers no more light, or in low light not enough photons may arrive to get above the noise floor of the sensor. Andy provided a 4-minute primer about solid state physics, including how a light photon can excite an electron to move up across the semiconductor’s “bandgap” and become stored charge on a particular pixel. He commented that we are very lucky that the energy of a visible photon is just about the right level to excite electrons across the bandgap in silicon and other common semiconductors; this fact makes it possible for us to use these materials as the photosensitive element in camera sensors.
CMOS image sensor arrays are used in less expensive cameras and are more power efficient, while CCD image sensor arrays used in more expensive cameras have better light sensitivity.
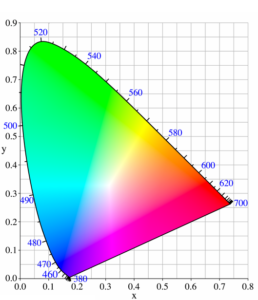
Chromaticity Diagram
Our eyes are only sensitive to the visible portion of the electromagnetic spectrum. A color wheel shows this spectrum range. A more sophisticated three-dimensional color wheel shows not just hue (color), but also saturation and value (or luminance). The eye has rods which register the amount of light for black and white vision, and three types of cones sensitive to different but overlapping wavelengths of light (L for seeing red, M for green, and S for blue). Because of the overlap, when you see green, there is also blue and/or red at the same time. A plane of constant luminance cutting through the 3-dimensional color space creates a 2-dimensional chromaticity diagram, which we use for camera work. We can only see colors within the boundaries of the chromaticity diagram.
Colors can be “added” or “subtracted”. For example, if we shine two flashlights with differently colored light onto a wall, the colors are added. If we combine colors in an oil painting, the colors are subtracted. In the case of the paint, each of the mixed colors absorbs certain light wavelengths. When mixed, there is more absorption than either color alone. This is color subtraction.
Color spaces can also be additive or subtractive. An example of an additive space is the “RGB color space” used for cameras and monitors. The subtractive space “CMYK” is used for printing. By choosing three primary colors we form a triangle, or “color gamut”, inside the chromaticity diagram, and we can only show colors within that triangle. A wider color gamut shows more subtle differences in hue and allows for less abrupt color shifting in mixed lighting. Indoor lighting can limit the possible colors you see in a photograph, so instead of a conventional tungsten, or especially LED, light, you may need to invest in a light source designed for photography that will more evenly illuminate a wide range of colors.
White balance is an important camera setting that compensates for the color of the light available where you are taking the photograph. You can calibrate the camera’s white balance to the current existing light, typically by use of a white card as a reference point. Some cameras have preset white balance settings, such as “daylight”, “tungsten light”, or “white fluorescent light”, each with a different “color temperature.” If the while balance is not set properly, the photo will wind up with a bluish or orange cast. If the camera saves the photo in RAW instead of JPEG format, then the white balance can be set in post-processing such as with Photoshop. However, with video it is very difficult to correct for improper white balance after the fact.
Color is detected in a camera using one of three methods. The oldest method uses three separate sensors with two prisms to separate the red, green, and blue colors. The more common method today uses a single sensor with a “Bayer filter,” a mosaic pattern with a combination of green, red, and blue color filters, and firmware to convert raw data into color data. Another new method uses a single sensor with three layers, but this is not common.
Cameras utilize sophisticated methods to compress the color data. For a given picture quality, the eyes need to see more detail about brightness than about color. This means that cameras can detect and store color data with lower resolution than the brightness. Engineers have developed methods called chroma subsampling to handle this reduced color data storage. Chroma subsampling was first used in the 1950’s to add color to black and white televisions. In digital cameras, the methods are different but the intent is the same. The amount of color data that is sampled and stored is specified by a 3-digit ratio like 4:4:4. The ratio 4:4:4 means that full color data is sampled and stored for every pixel. The most common ratio is 4:2:0, and this means that color data is stored at a resolution a quarter that of the brightness.
Mark and Andy also discussed the cameras they brought in to display, and they took some final questions from the audience.
